이제 CNN을 넘어서 DSL의 마지막 챕터인 RNN까지 왔다. 저번엔 주로 이미지를 어떻게 처리하는지 배웠다면 이번엔 음성, 자연어 등의 시퀀스 데이터를 어떻게 처리하는지에 대해서 배운다. 첫 강의 때 여러 시퀀스 데이터의 예시를 보면서 지금까지는 당연히 입력이 시퀀스 데이터겠거니 하던 생각을 고쳐먹을 수 있었다. 음악 생성 알고리즘 같은 경우엔 입력은 없을 수도 있고 출력은 당연히 시퀀스 데이터다. 저번 학기에 캡스톤 프로젝트를 하면서 NLP 맨땅에 헤딩을 해봤기 때문에 용어는 어느 정도 익숙한 게 다행이라면 다행인 것 같다.
1. RNN
처음 시작하는 분야니까 notation부터 정리할 필요가 있다. 이전과는 다르게 < > 괄호가 생겼다. 지금까지 사용했던 데이터와는 다르게 순서(시간) 개념이 들어가기 때문이다. 이전처럼 ( ) 괄호는 몇 번째 데이터인지 나타낸다. 그리고 one hot vector라는 걸 사용해서 입력 데이터를 표현한다. 이 예시에서는 y가 사람 이름인지 아닌 지로 결정된다.

그리고 RNN의 구조는 대충 이렇게 생겼다. 왼쪽 그림과 오른쪽 그림은 같은 RNN을 표현하는 다른 방식이다. 오른쪽에 비해 왼쪽이 훨씬 직관적인 것 같다. 그리고 그 밑은 그림을 표현한 식인데 왼쪽을 오른쪽처럼 간단하게 표현할 수 있다. 가중치로 사용하는 w_ax, w_aa 등의 의미는 아래 첨자의 첫 번째 문자는 계산 결과를 나타내고 두 번째 문자는 가중치가 붙는 변수를 나타낸다. 따라서 a를 계산하는데 x에 붙는 가중치라면 w_ax가 된다. a를 계산할 때는 주로 tanh와 ReLU를 activation function으로 사용하고 y를 계산할 때는 sigmoid를 사용한다.

밑은 back propagation이 어떤 식으로 진행되는지를 나타낸 그림이다. 이전에 비해서 파라미터가 덜 다양하게 사용되는 것 같다.

2. Different Types of RNNs
지금까지는 T_x와 T_y와 같다고 생각하고 이야기를 진행했다. 하지만 RNN은 다양한 입력과 출력을 가질 수 있다. One to one부터 many to many까지 다양하다.

3. Language Model
Language Model이란 어떤 임의의 문장이 주어졌을 때 그 문장이 맞을 확률이 얼마나 되는 지를 알아내 준다. 예를 들어서 "The apple and pair salad"와 "The apple and pear salad" 둘의 확률은 아무래도 후자가 더 알맞은 문장일 확률이 더 높을 것이다.
만약 "Cats average 15 hours of sleep a day. <EOS>"라는 문장을 학습한다면 첫 단어가 'Cats'일 확률부터 시작해서 'Cats' 다음에 'average'가 올 확률, 'Cats average' 다음에 '15'가 올 확률을 계산해나간다.

이 모델을 학습시키기 위해서는 토큰화 된 문장이 필요하다. 보통 단어 단위로 토큰을 끊는다. 내가 임의로 정한 단어 사전에 포함되어 있지 않은 단어의 경우 등으로 표현한다. 그리고 단어 단위가 아니라 문자 단위로 끊을 수도 있다. 문자 단위로 하면 <unk> 같은 건 필요 없지만 계산량이 훨씬 늘어날 수 있다.
그리고 학습된 모델을 사용해서 임의의 문장을 샘플링할 수도 있다. 샘플링하는 방법도 첫 단어를 결정하고 다음 단어로 올 수 있는 단어들의 확률을 계산하면서 문장을 만들어 나간다.
4. Gradient Vanishing and Exploding
RNN 모델에서는 이런 문제가 자주 발생한다. 자연어 문장에는 단어와 단어 사이의 종속성이 있을 수 있는데, 바로 옆에 있는 단어끼리 관계가 있을 수도 있고, 문장의 끝과 끝 사이에도 그런 종속성이 있을 수 있다. 하지만 RNN은 이런 장기 종속성을 파악하는 데에는 한계가 있다. 그리고 RNN은 레이어가 깊기 때문에 이런 문제가 더 자주 발생하기도 한다. 정확히는 레이어가 깊다고 할 수는 없을 것 같긴 한데, 아무튼 가중치를 여러 번 곱한다고 보면 될 것 같다.
Grandient Exploding은 gradient clipping이라는 기법을 사용해서 처리할 수 있다. 어떤 임계값을 설정하고 절대 값이 그 이상으로 커지면 그냥 값을 잘라버리는 방법이다. 하지만 소실 쪽 문제는 해결하기가 까다롭기 때문에 RNN에서 변형된 모델들이 나오기 시작했다.
5. Gated Recurrent Unit (GRU)
위에서 말한 문제를 해결하기 위한 방법으로 제시된 모델 중에 하나다. NLP 무지렁이인 나도 들어봤을 정도니 이게 처음 학계에 소개됐을 때는 파괴력이 엄청났을 것 같다. 여기서 사용하는 c는 이전에 사용했던 a랑 똑같다. 하지만 이후 LSTM에서 다른 값을 가지기 때문에 표시를 바꿨다고 한다. GRU는 gamma를 도입해서 장기 종속성을 표현할 수 있게 됐다. 이게 게이트다. 이 gamma는 0에 가깝거나 1에 가까운 값을 가지는데. 만약 gamma가 1이라면 값을 갱신하고 아니라면 이전 값을 유지한다. 그래서 c tilda는 c <t>가 될 수도 있는 후보라고 받아들이면 된다. 그리고 이 식에서 사용되는 변수들이 스칼라라고 생각하면 뭔가 말이 안 되는 것 같은데 이 모든 변수들은 벡터이기 때문에 말이 된다.

위의 그림은 좀 단순화한 GRU고 실제로는 gamma가 하나 더 있다. u는 update, r은 relevant의 약자다. u는 값을 경신할 건지 말 건지를 결정하고 r은 이전 값을 얼마나 끌고 올 건지 결정한다고 생각하면 될 것 같다.
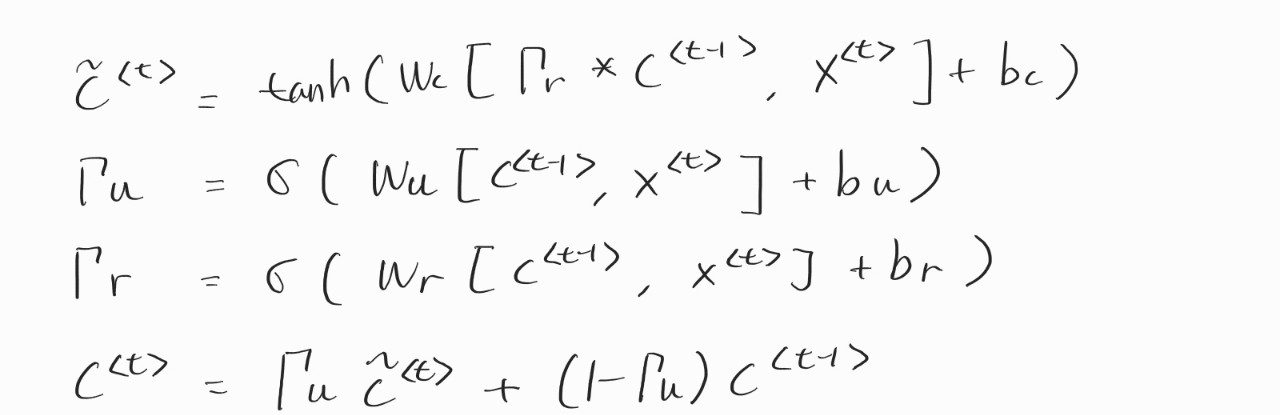
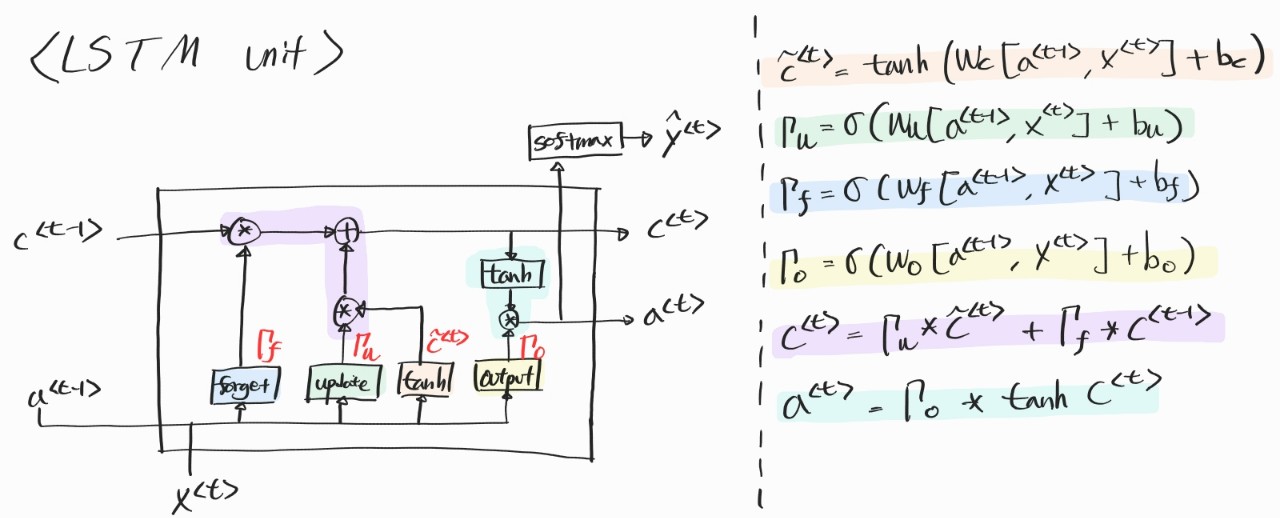
6. Long Short Term Memory (LSTM)
사실은 LSTM이 GRU보다 훨씬 먼저 나온 개념이다. LSTM은 3개의 update, foreget, output 게이트를 사용한다. 조금 그림이 복잡한듯하지만 식을 보고 그림을 보면 이해가 더 잘된다. 그림이 더 이해 잘 되라고 그린 게 아닌가 싶긴 한데 나는 식이 더 이해가 잘 됐던 것 같다. 게이트라는 용어가 등장하기도 하고 그림을 그려놓고 보면 확실히 회로 같긴 하다.
7. Bidirectional RNN
지금까지의 모델을 순방향으로만 정보가 전달됐다. 그래서 한 세 번째쯤에서 y를 만들고 싶으면 그 전의 정보들만 사용할 수 있었다. 하지만 실제로는 문맥이라는 게 앞의 정보만 사용한다고 되는 것은 아니기에 양방향으로 정보를 전달할 필요가 있다. 그림에서 사용된 블록은 RNN일 수도 있고, GRU, LSTM 블록을 사용할 수도 있다.
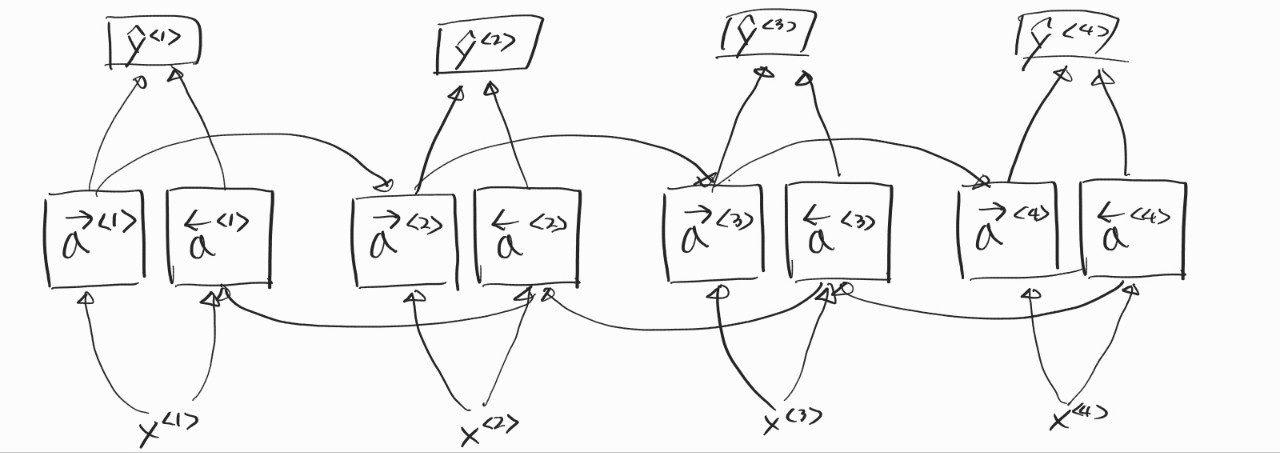
처음부터 끝까지의 모든 정보가 필요하기 때문에 중간 중간 y를 뱉을 수가 없다. 때문에 음성을 듣고 실시간으로 통역을 해주는 어플에서는 이 방법이 효과적이지는 않지만 한 번에 모든 문장을 볼 수 있는 자연어 처리에서는 꽤나 효과적으로 사용된다.
8. Deep RNN
보통의 RNN에 비해서 더 복잡한 문제를 해결해야 할 때 이 구조를 사용하면 조금 더 성능이 좋을 수 있다. 각각의 블록을 GRU나 LSTM로 사용할 수도 있다. 보통 이런 구조에서는 LSTM을 사용하는 듯하다. 대신 이전의 CNN 처럼 깊게는 레이어를 쌓지 않는다. 3개 정도만 돼도 꽤나 많은 거라고 한다.
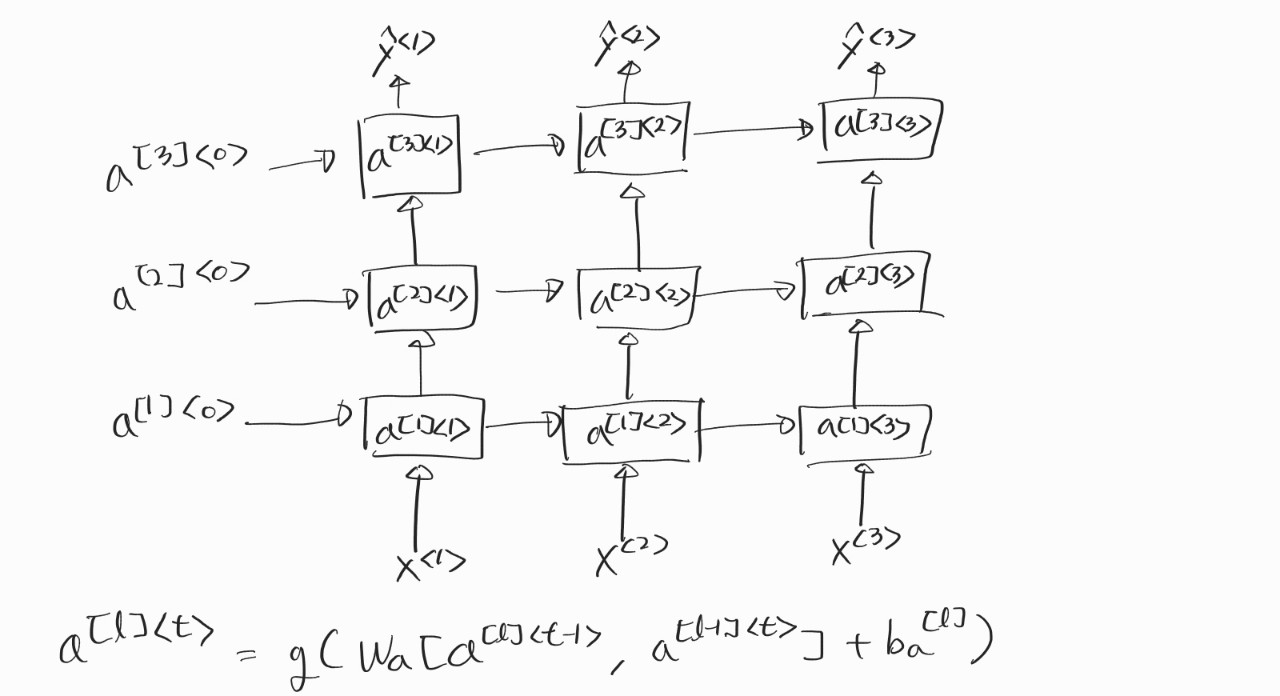
이번 주차는 GRU, LSTM이 어떻게 동작하는지가 제일 핵심이었다고 생각한다. 고작 강의 두 시간 들은 걸로 전부 이해했다고는 할 수 없지만 어느 정도 가닥은 잡을 수 있었다.
* Courera의 Deep Learning Sepcialization 강의를 수강하는데 도움이 되고자 작성한 요약문입니다. 틀린 내용 있다면 정정해주시면 감사하겠습니다.