이번 주차에는 객체 탐지에 대해서 배울 요량인가 보다.
1. Object Localization & Landmark Detection
본격적인 객체 탐지를 시작하기 전에 맛보기 도메인 이해를 높이기 위한 주제 정도였던 것 같다. 우선 객체 탐지에서는 한 이미지에 객체가 여러 개 있을 수 있다. 대신 지금 말하는 이미지 분류에서는 객체가 하나밖에 없다고 생각하자. 이미지에서 내가 원하는 것을 찾도록 학습을 시키기 위해서는 이미지에 라벨을 붙여서 지도 학습을 해야 된다. 라벨을 도대체 어떻게 붙여야 잘 붙였다고 소문이 날까? 우선 이미지에 어떤 객체가 있는지에 대한 라벨이 필요하다. 내가 찾고 싶은 객체가 자동차, 보행자, 나무라면 이미지마다 각각의 라벨을 붙여줘야 한다. 그리고 그 객체가 어디 있는지에 대해서도 찾고 싶다면 위치에 대한 정보도 라벨을 붙여줘야 한다. 그림에 있는 x, y 값은 bounding box의 중앙이고 h, w 값은 그 bounding box의 높이와 넓이를 표현한다.
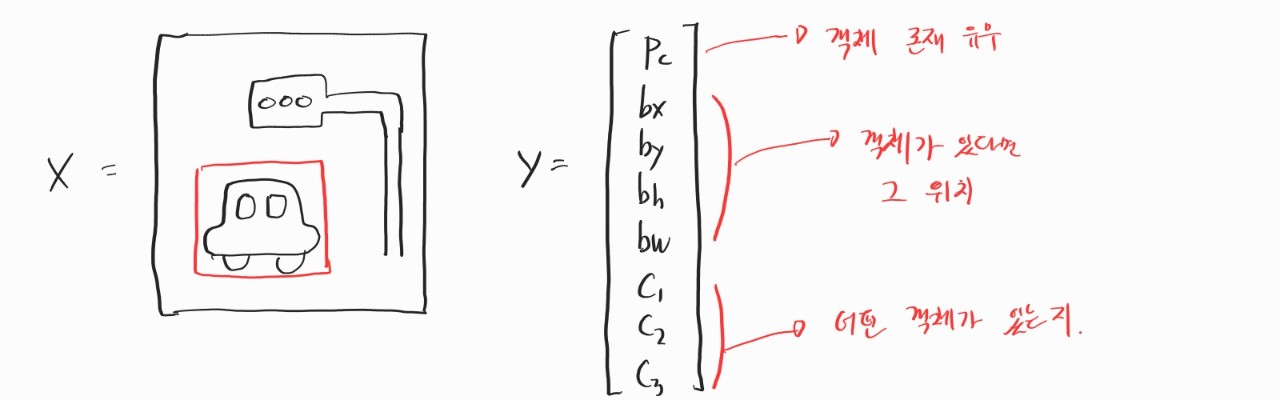
라벨을 붙였다면 모델에 넣어서 학습을 시켜야 된다. 그럼 학습은 어떻게 시킬까? 위의 예시대로라면 출력이 8개 필요하다. 이때 값들의 성격이 조금씩 다르기 때문에 그냥 무지 성으로 값을 뱉을 수는 없다. 특히 어떤 객체인지에 대한 정보는 소프트맥스를 사용해서 값을 결정해야 한다. 그럼 loss function은? 객체 존재 유무에 따라서 다르다. 물론 실제로는 한 번에 식을 구현하는 방법이 있을 것 같다. 당연히 오차 제곱 말고도 다른 방법도 있겠지.

그리고 landmark detection은 object localization과 상당히 유사하다. 대신 문제를 어떻게 정의하느냐에 따라 조금씩 차이가 있다. 얼굴 인식에서는 사람의 눈꼬리, 입꼬리 등을 랜드마크로 설정하고 라벨을 붙인다. 다른 예시로는 팔꿈치, 무릎 등을 랜드마크로 설정해서 사람의 포즈를 인식할 수도 있다.

2. Sliding Window
본격적인 객체 인식을 하기 전에 계속 배경 지식을 쌓는 중이다. Sliding window는 작년쯤에 알고리즘 문제를 풀면서 처음 들어봤다. 물론 정확히 똑같은 알고리즘은 아니겠지만 어느 정도 궤가 같은 이야기들이다. 이 window라는 용어는 컴퓨터 과학 분야에서 참 잘 쓰이는 것 같다. 여기저기서 많이 들린다.
아까도 말했지만 객체 탐지에서는 한 이미지에 객체가 여러 개 일 수도 있다. 그럼 이걸 다 어떻게 찾냐? 아직 강의를 다 듣지 않아서 더 좋은 방법이 있을 수도 있지만, sliding window는 일종의 brute force 알고리즘이다. 그냥 임의의 크기로 박스를 설정하고 그걸 이동하면서 이미지가 있는지 없는지 검사하고 박스 크기를 조금 키워서 또 반복한다. 때론 이렇게 무식한 방법이 잘 통할 때도 있다. 대신 효율적이냐고 하면 그렇지는 않은 것 같다. 이미지의 크기랑 박스 크기를 잘못 설정하면 연산 비용이 어마 무시할 것 같다. 또 재수 없는 경우에는 모든 박스에 객체가 잘려서 들어올 수도 있다는 문제가 있다.

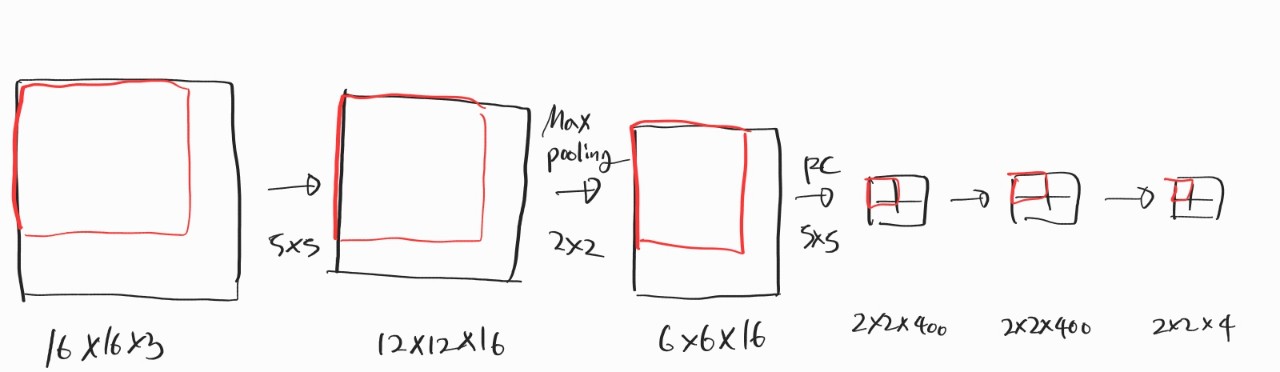
우선 계산 비용을 줄이기 위해서는 박스를 옮기는 과정을 순차적으로 실행하는 게 아니라 convolution을 활용해서 한 번에 하면 된다. 그전에 fully connected layer를 convolution으로도 구현할 수 있다는 사실을 먼저 알아야 한다. 생각해보면 그리 어렵지 않다. 그냥 사이즈 맞춰서 convolution 연산만 해주면 똑같은 차원으로 구현할 수 있기 때문이다. 그다음에는 convolution 연산이랑 pooling을 섞어주면 논리적으로 sliding window와 똑같게 된다. 그냥 필터를 중복해서 사용할 뿐이다. 하지만 여전히 객체가 있는 위치를 박스로 정확하게 알아낼 수 없다는 문제점이 존재한다.
3. YOLO Algorithm
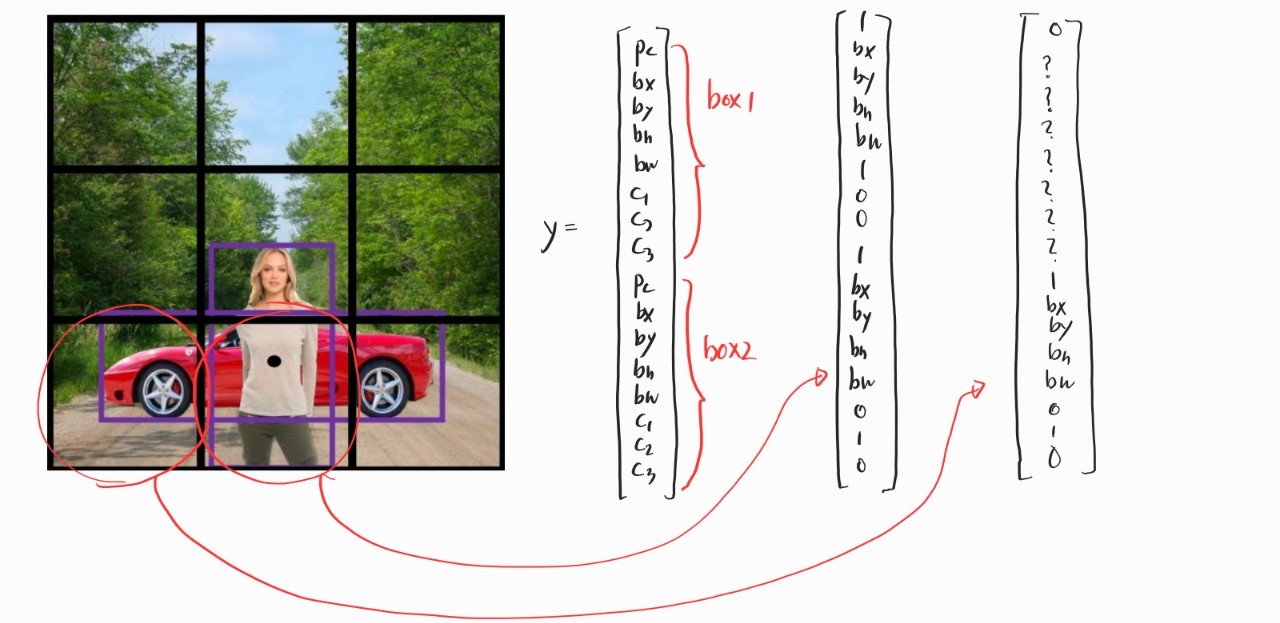
그래서 나온 게 YOLO 알고리즘이다. 이 알고리즘의 핵심 아이디어는 이미지를 쪼개는 것이다. 그리고 각각의 조각마다 라벨을 붙인다. Object localization에서 사용했던 예시랑 똑같이 라벨링 한다고 생각하자. 그리고 이미지를 3x3으로 쪼개면 출력은 3x3x8의 차원을 갖게 된다. 그리고 각각의 조각은 객체의 중심을 기준으로 해서 라벨링 한다. 여러 조각에 걸쳐 있는 객체라도 중심을 기준으로 객체의 위치를 선정한다. 그리고 각각의 조각마다 좌표를 새로 (0,0)부터 (1,1)까지 설정한다. 따라서 객체가 있는 조각에서 x, y 값은 0과 1 사이일 수밖에 없지만 w와 h 값은 1을 넘을 수도 있다.

결국에 이 방법은 일종의 분할 정복법이 아닌가 하는 생각이 든다. Object detection 문제 하나를 object localization 문제 여러 개로 만드는 방법으로 이해했다. 그리고 이 YOLO 알고리즘은 밑의 두 개의 방법을 더해서 성능을 더 높일 수 있다.
4. Non-max Suppression
지금까지 배웠던 알고리즘을 이미지에 적용하면 이미지에는 객체가 하나뿐인데 여러 격자에서 객체를 찾았다고 할 수도 있다. 그래서 지가 객체를 찾았다고 주장하는 격자들을 가장 가능성 있는 하나로 정리하기 위해서 이 알고리즘을 사용한다. 우선 IoU 개념이 필요하다. Intersect over Union을 한국말로 번역하면 합집합의 교집합(?) 정도가 되려나. 그림처럼 객체라고 인식한 두 개의 직사각형이 얼마나 겹치는지를 측정하는 지표다. 보통은 0.5를 기준으로 겹쳤는지 안 겹쳤는지 판단하는 것 같았다.

아무튼 non-max suppresion에서는 이 IoU 값을 사용해서 중구난방으로 감지된 객체를 정리한다. 이때 Pc라는 값을 기준으로 사용한다. 이 값은 감지된 직사각형이 객체가 맞을 확률 정도라고 생각하면 될 것 같다. 예를 들어, 가장 처음에는 0.6 미만의 Pc 값을 같은 직사각형은 다 무시한다. 그 이후에 남은 직사각형 중 Pc 값이 가장 높은 직사각형을 고르고 그 직사각형과 IoU 값이 높은 직사각형들을 지운다. 이 과정을 더 이상 살펴보지 않은 직사각형이 없을 때까지 반복한다. 골랐던 직사각형들만 객체로 인식한다.
5. Anchor Boxes
이 알고리즘은 한 격자 안에 객체가 여러 개 들어있는 경우를 처리하기 위한 알고리즘이다. 지금까지는 당연히 한 격자에 한 객체만 들어있다고 가정했었지만 실제로는 그렇지 않을 수도 있다. 특히 격자를 촘촘히 나누면 이런 경우는 거의 발생하지 않지만, 그렇지 않은 경우에는 충분히 일어날 수 있는 일이다.
우선 K-means 알고리즘 등을 이용해서 achor box의 모양을 정한다. 그리고 사용할 box의 개수도 정해야 한다. 만약에 box가 두 개라면 한 격자에 두 개의 객체가 들어있는 경우는 처리할 수 있지만 세 개 이상은 어렵다. 이전과 동일하게 한 격자마다 라벨링 한다. 대신 원래에 비해서 차원이 늘어나게 된다. 어떤 객체를 어떤 anchor box에 맵핑하는지는 anchor box와 객체의 IoU를 사용한다.
원래는 3x3으로 나눈 이미지에 대해서 y의 차원이 3x3x8이었다면 이제는 anchor box를 두 개 사용하기 때문에 3x3x16 혹은 3x3x2x8이 된다.
6. U-Net
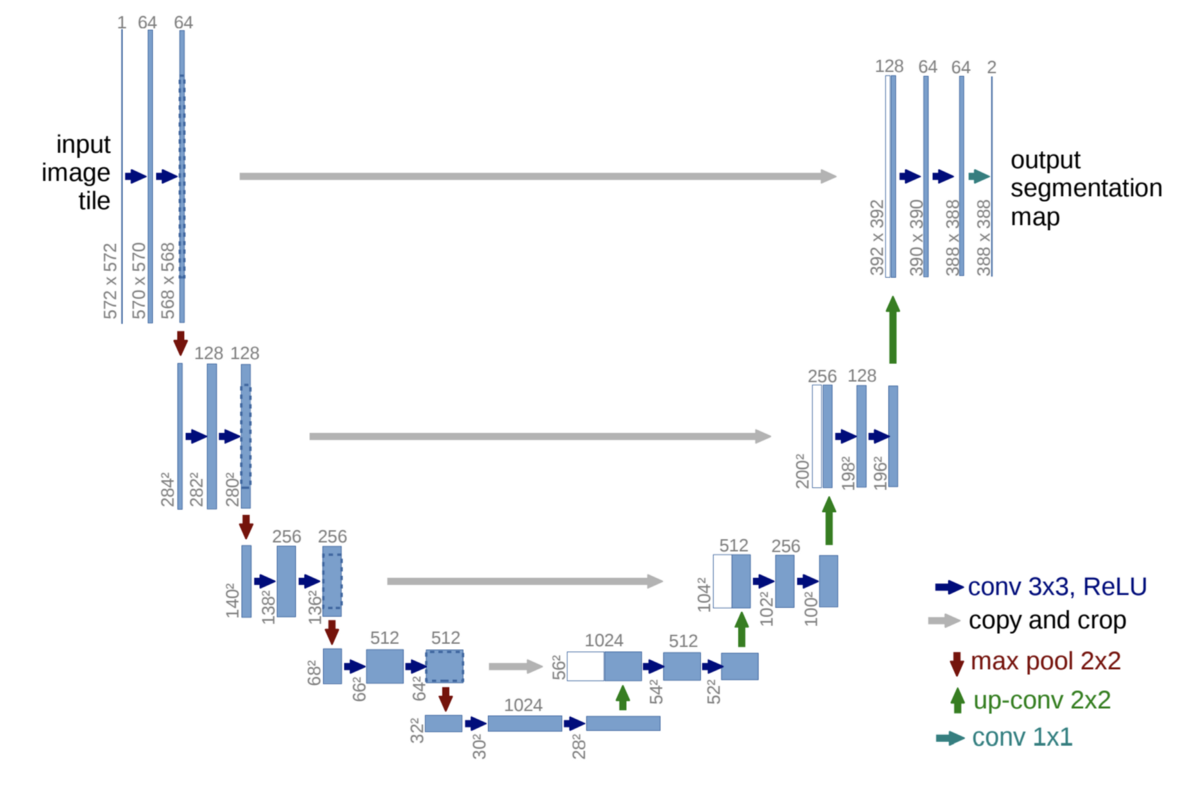
지금까지는 그냥 객체 탐지를 하기 위해서 그냥 객체에 박스를 쳤다. 그런데 객체의 테두리를 따고 싶다던가 해서 이미지에 픽셀 단위의 라벨링이 필요할 수도 있다. 이럴 때 이 U-Net이라는 구조를 사용한다. 지금까지의 CNN은 HxWx3 크기의 이미지를 입력으로 받으면 그것보다 작은 차원으로 결과를 뱉었다. 하지만 U-Net은 채널 크기가 HxW에다가 채널의 개수는 이미지에 있는 객체만큼 뱉는다. 원래 convolution 연산을 하다 보면 채널 하나하나의 크기가 감소하기 마련인데 어떻게 결과의 크기가 똑같을까? 이는 transpose convolution 연산을 하기 때문이다. 보통의 convolution 연산을 거꾸로 하는 느낌이다.

그리고 U-Net은 convolution 연산을 통해서 해상도는 낮지만 문맥 정보가 높은 결과에다가 해상도가 높지만 문맥 정보가 낮은 이전의 결과를 skip connection을 한다. 만약 고양이 이미지에 대한 semantic segmentation을 하는 경우에 전자는 고양이가 사진의 어디쯤 있는지에 대한 정보라면 후자는 실제로 고양이가 어떤 모양을 가지고 있는 지에 대한 정보일 수 있다. 아무튼 U-Net은 전체적인 흐름을 그리면 U자 모양이라서 U-Net이란다. 실제로는 복잡한 구조겠지만 굉장히 단순화된 직관만 적어뒀다.
일 년 전만 해도 컴퓨터 비전이 뭔지도 몰랐는데, 이젠 대충 어떤 방식으로 작동하는 건지에 대해서 알게 됐다.
* Courera의 Deep Learning Sepcialization 강의를 수강하는데 도움이 되고자 작성한 요약문입니다. 틀린 내용 있다면 정정해주시면 감사하겠습니다.