Week 2에는 이진 분류 문제를 해결하기 위해 상당히 간단한 Logistic Regression 모델을 만들었다. Week 3에는 이 모델을 조금 더 확장하는 방법에 대해서 배웠다.
역시 새로운 notation부터 정리하는 게 정신 건강에 이롭다. 우선 각각의 동그라미는 노드라고 부른다. 그리고 층이 하나 더 생기면서 위 첨자로 [1], [2]가 생긴 걸 볼 수 있다. Input Layer를 [0]이라고 생각하고 왼쪽부터 오른쪽으로 번호를 하나씩 증가시킨다. 여기서는 Hidden Layer가 하나밖에 없기 때문에 [1]이 Hidden Layer이고 [2]가 Output Layer다. Hidden Layer의 이름이 Hidden인 이유는 노드 값을 실제로 관찰할 수 없기 때문이다. 억지로 계산하지 않는 이상은 볼 수 없어서 이런 이름이 붙은 것 같다.

이제 이걸 어떻게 벡터로 표현할지 고민하기 위해서 일단 스칼라로 식을 쓰고 벡터로 변환해보자. 우선 Hidden Layer의 z 랑 a부터 바꾸자. 아직까지는 Hidden Layer의 Activation Function도 시그모이드로 쓰기 때문에 Week 2랑 똑같은 방법으로 구하면 된다. 아직 익숙하지 않은 notation만 조금 조심하자. 여기서 헷갈렸던 게, w에서 W가 되면서 z를 구할 때 더 이상 전치를 하지 않아도 된다는 점이었다. W엔 이미 전치된 녀석들이 들어간다는 사실을 염두에 두자. a는 그냥 Z에 시그모이드 취하면 된다. 얘는 헷갈릴만한 내용 없다! 그림의 색깔은 위랑 전혀 상관없다. 그림의 z는 Z가 아니라 z이다(소문자임).

그래서 벡터로 모든 a, z, W 값을 구해보면 다음과 같다. 위에서 한번 언급했듯이 W는 더 이상 transpose하지 않는다. 여기도 z는 소문자다.

지금까지는 Single Train Set에 대해서 문제를 해결했다. 이젠 당연히 m개의 Train Set에 대해서도 문제를 해결해야겠지? 위의 방법으로 m개를 for문으로 처리하면 되기는 된다. 그림의 [1]은 Hidden Layer라는 뜻이고, (i)는 Train Set의 번호다.

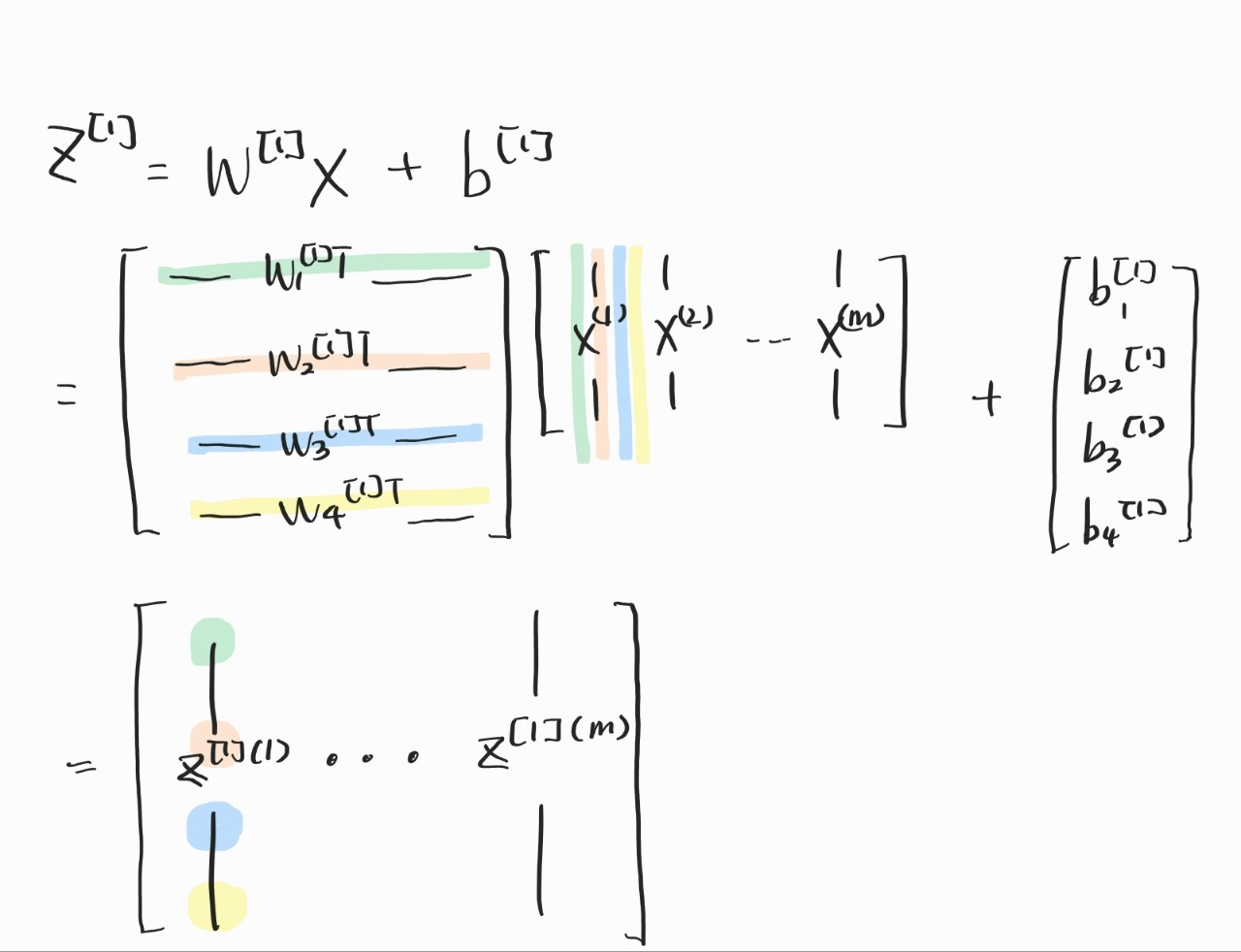
하지만 이걸 벡터로 야무지게 해결할 수 있다. 앤드류 응 교수님은 벡터를 사용하면 계산 속도도 더 빨라진다고 하셨다. 역시 뭐든지 빠른 게 최고다. X, Z, A를 그림처럼 정의하고 Output Layer 값을 구하는 방법을 적었다. 여기서부터는 드디어 Z가 대문자가 됐다. 여기서 Z, A 행렬의 행 개수는 Layer의 노드 개수고, 열은 Train Set의 개수라고 생각하면 된다.

근데 여기서 W를 그냥 똑같이 써도 되나 싶었다. 곰곰이 생각해보니 안 될 이유가 없었다. 손으로 써보니 확실히 이해가 됐다. 행렬이 익숙하지 않다 보니, 바로바로 머리에 안 들어와서 손이 고생이다. 아무튼 이런 방식으로 Z랑 A 계산이 가능하다.
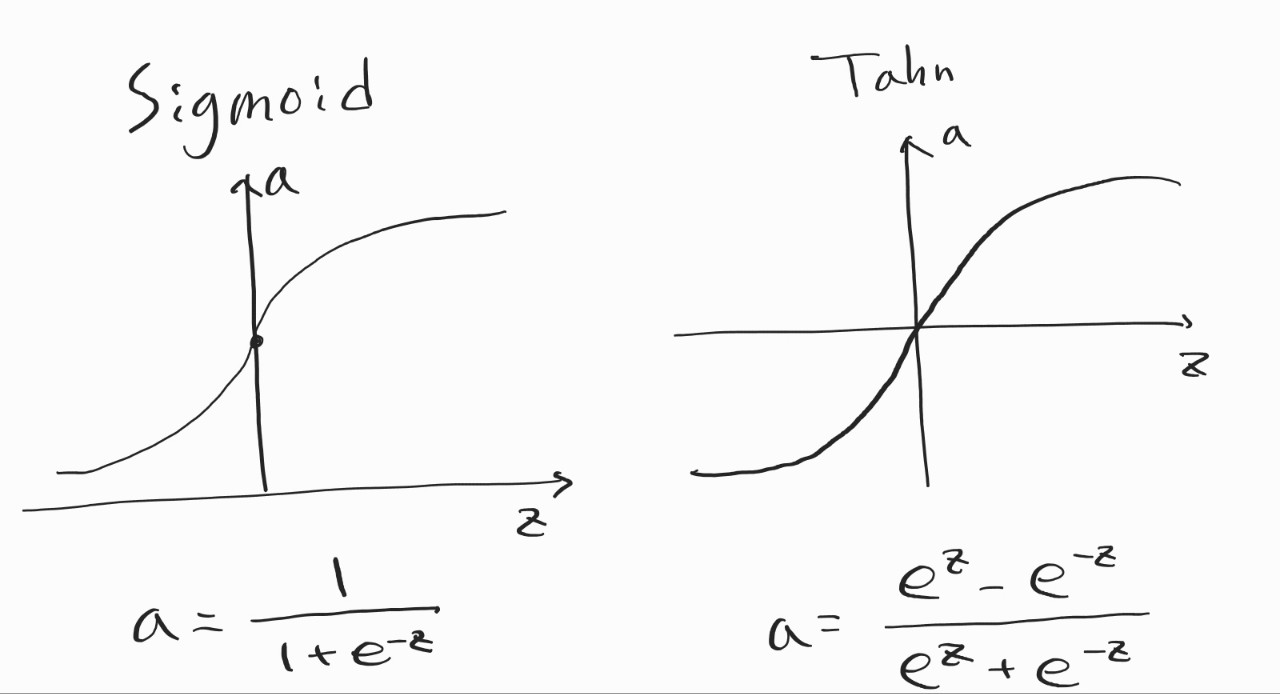
그다음엔 Activation Function. 지금까지 Hidden Layer의 Activation Function을 그냥 시그모이드로 사용했었다. 하지만 시그모이드는 이진 분류 모델의 Output Layer에서 쓸모 있는 것에 비해, Hidden Layer에선 글쎄올시다이다. 그래서 Tanh를 사용하기도 하는데, 얘도 그다지이다. 그 이유는 둘 다 z 값이 커지면 기울기가 0에 수렴하기 때문에 학습이 잘 진행되지 않기 때문이다.
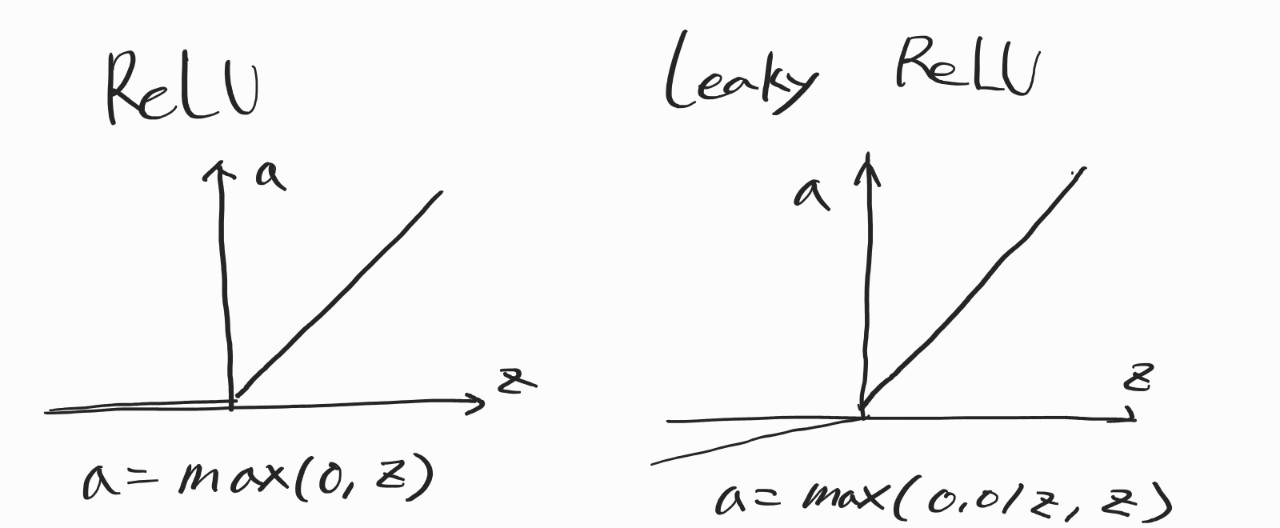
그래서 사용하는 것이 ReLU, Leaky ReLU다. 얘네는 z 값이 커져도 기울기가 일정하다. z가 정확히 0일때 미분 불가능하긴 하지만 크게 문제가 되지는 않는다.
이쯤에서 왜 Activation Function으로 a=z 같은 선형 함수를 안 쓰나 했더니 바로 다음 강에서 설명하시더라. 그 이유는 선형 함수를 사용하게 되면 Hidden Layer의 노드들이 의미가 없어지기 때문이다. 선형 활성 함수를 쓰면 Hidden Layer가 없는 것보다 오히려 성능이 더 떨어진다고 한다. 그래도 이진 분류 문제 말고 선형 회귀 문제를 풀 때는 마지막 출력층에서 사용하긴 한다.
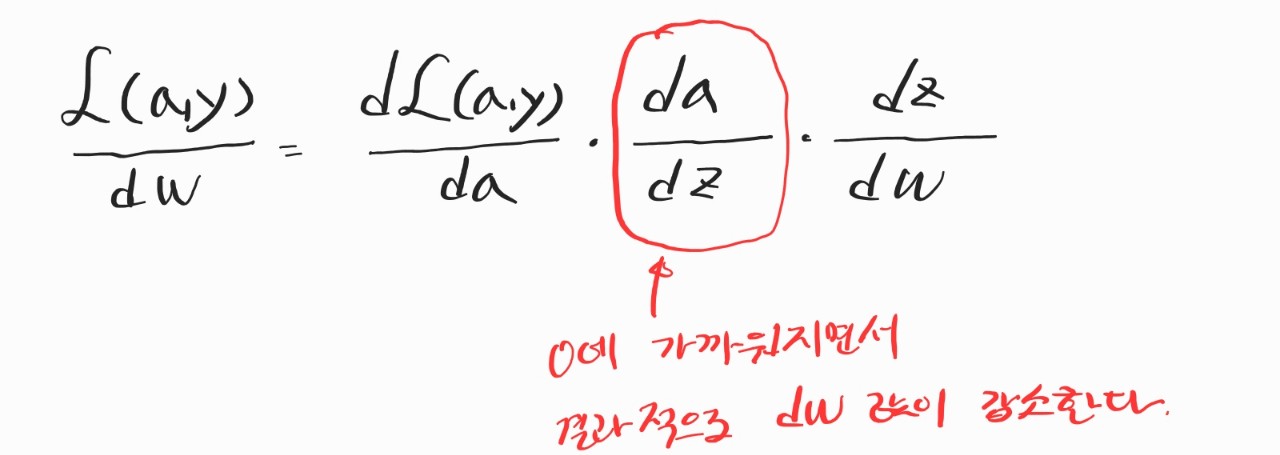
Gradient Descent는 이전보다 Layer가 하나 늘긴 했지만, 별로 안 어려울 것이라고 생각했는데 그건 오산이었다. 그냥 바로 어지러워졌다. 내가 이해를 못 한 건지, 설명을 꼼꼼히 안 하신 건진 모르겠는데 특히 dz [1] 구하는 부분에서 그냥 우주로 날아가버렸다... 나머지는 어찌어찌 이해했는데 dz[1]만큼은 여전히 모르겠다... 행렬 미적분학을 공부를 해야 이해할 수 있을 것 같다. 그래도 Backpropagation이 뭐하는 놈인지 어느 정도 감을 잡을 수 있었다. 아무튼 Gradient Descent 방법은 적어두고 마무리해야겠다.
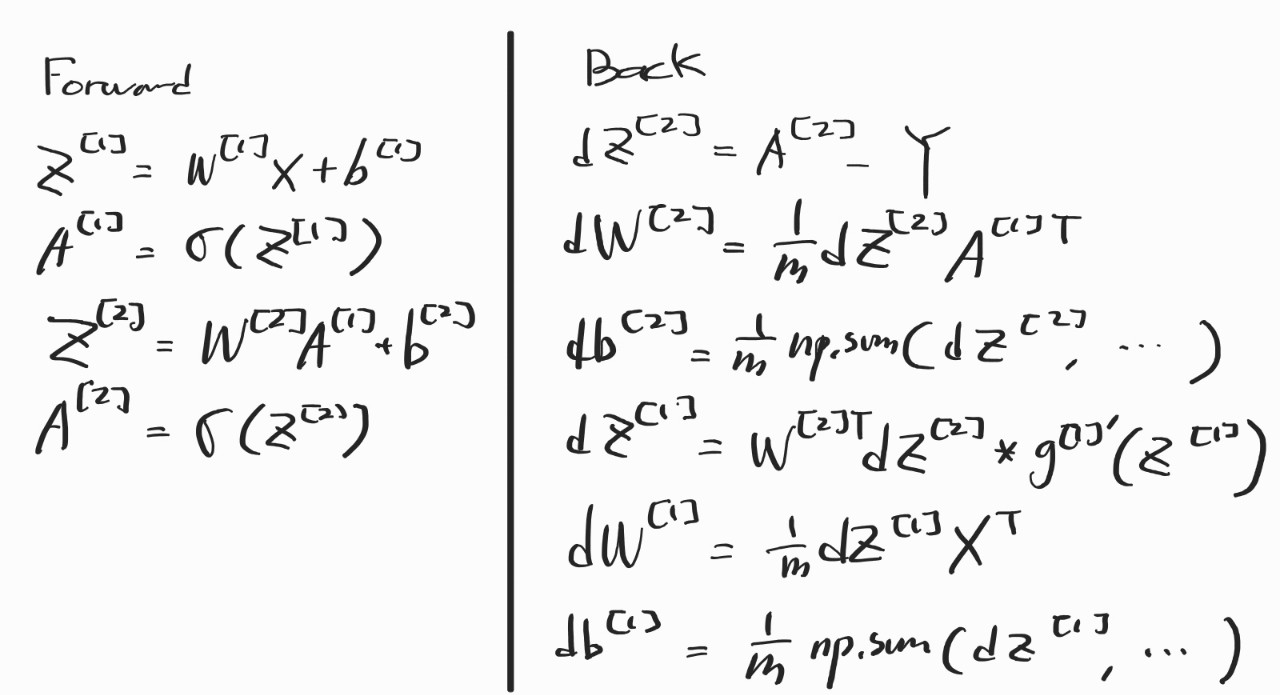
마지막으로는 가중치를 처음에 0으로 초기화하면 안되는 이유를 설명하셨다. 이전 주차의 프로그래밍 과제에서는 0으로 했던 것 같은데 왜 안되지? 하는 의문이 있었다. 그 이유는 Neural Network에서 그냥 가중치를 0으로 만들어버릴 경우엔 모든 노드가 똑같은 계산을 하기 때문이었다. b는 모두 0으로 초기화해도 되는데 W 만큼은 그러면 안 된다.
* Courera의 Deep Learning Sepcialization 강의를 수강하는데 도움이 되고자 작성한 요약문입니다. 틀린 내용 있다면 정정해주시면 감사하겠습니다.
'etc > 구글 머신러닝 부트캠프' 카테고리의 다른 글
| [DSL] Improving Deep Neural Networks Week 2 : Optimization Algorithms (0) | 2022.07.02 |
|---|---|
| [DSL] Improving Deep Neural Networks Week 1 : Practical aspects of Deep Learning (0) | 2022.07.01 |
| [DSL] Neural Networks and Deep Learning Week 4 : Deep Neural Network (0) | 2022.06.30 |
| [DSL] Neural Networks and Deep Learning Week 2 : Neural Networks Basics (0) | 2022.06.29 |
| [구글 머신러닝 부트캠프] 킥오프 미팅 (0) | 2022.06.23 |